ETR recently conducted two thought leadership webinars with executives from AI coding assistant company Tabnine. The first part of the series focused on the higher-level impacts of generative AI in the workplace and its role in code generation, while the second part took a technical deep-dive into how tools like Tabnine's work.
Part 1 of the series featured an interview with Peter Guagenti, Tabnine's President and Chief Marketing Officer. Guagenti discussed the state of generative AI and its impact on organizational workflows, particularly in software development, and the shift in executive mindset towards embracing AI. He described how to best leverage AI for code generation, documentation, and unit testing; the importance of prompt engineering and context; the evolving capabilities of AI assistants, agents, and future AI engineers; lingering cultural barriers to AI adoption; and the need for robust privacy and data protection.
Part 2 featured an interview with Eran Yahav, Tabnine's CTO and Co-Founder. Yahav detailed his company’s vision of automating software creation and maintenance through AI. Already integral to the software development lifecycle, Yahav predicts AI assistants will quickly become more autonomous agents, and ultimately evolve into “AI engineers,” capable of taking projects from ideation to production with minimal human intervention. Tabnine has implemented comprehensive context, evaluation, and control layers across all of its systems, easily tailored to a software architect’s specific vision and company best practices.
Select highlights from the two ETR Insights interviews are below, but you can watch the full webinar replay or check out the full summaries of both parts in the series on the ETR platform for additional context.
Part 1: Interview Highlights
Tabnine, which created the first AI code assistant in 2018, has seen growth to a million monthly active users driven by individual developers who recognize the technology's potential. C-suite executives are also now racing to adopt and benefit from AI; Tabnine is second only to Microsoft Copilot among those deploying automated code generation. “ChatGPT changed everything,” notes Guagenti, “because all of a sudden it demonstrated to us what was actually possible with these large language models.” Compared to customer support and chatbots, AI-generated software is relatively mature. “We're still in V.1, but it's leapfrogging as we add capability, and I'm excited to be a part of it.”
Guagenti describes the greatest barrier to adoption as cultural; many still worry that AI will ultimately replace human developers. He encourages users to instead think of Tabnine as an “Iron Man suit for the mind,” making developers more efficient and effective. “When we wrote applications before, we had to do things like memory management—and before that, we used to stuff index cards into a machine. We don't do those anymore, but there are still software engineers.”
Ultimately, Guagenti imagines a future of automated software ‘engineers’ capable of generating applications directly from project specifications, or efficiently reusing existing proprietary code. “We have a fully functioning AI engineer today that can take a Jira ticket and turn it into a simple node application.” Human oversight, however, will be required for the foreseeable future. “When you start building a lot of these capabilities in, the complexity of software means the current model of just feeding something requirements and getting something back probably isn’t going to work. It's going to be a different way of working with each other between the AI and the human, to do this where it actually works.”
On competitors, “Most people don’t understand what it takes to build one of these tools.” Guagenti reflects on the intricate engineering behind Tabnine’s products; this accumulated knowledge, coupled with robust integrations across major IDEs and Git systems, offers a formidable moat. “We think there's more than enough of a market for us to be a strong independent business as we [serve] the 100 million people who touch software development in the world today, and we’ve built some really unique and killer IP to do that.”
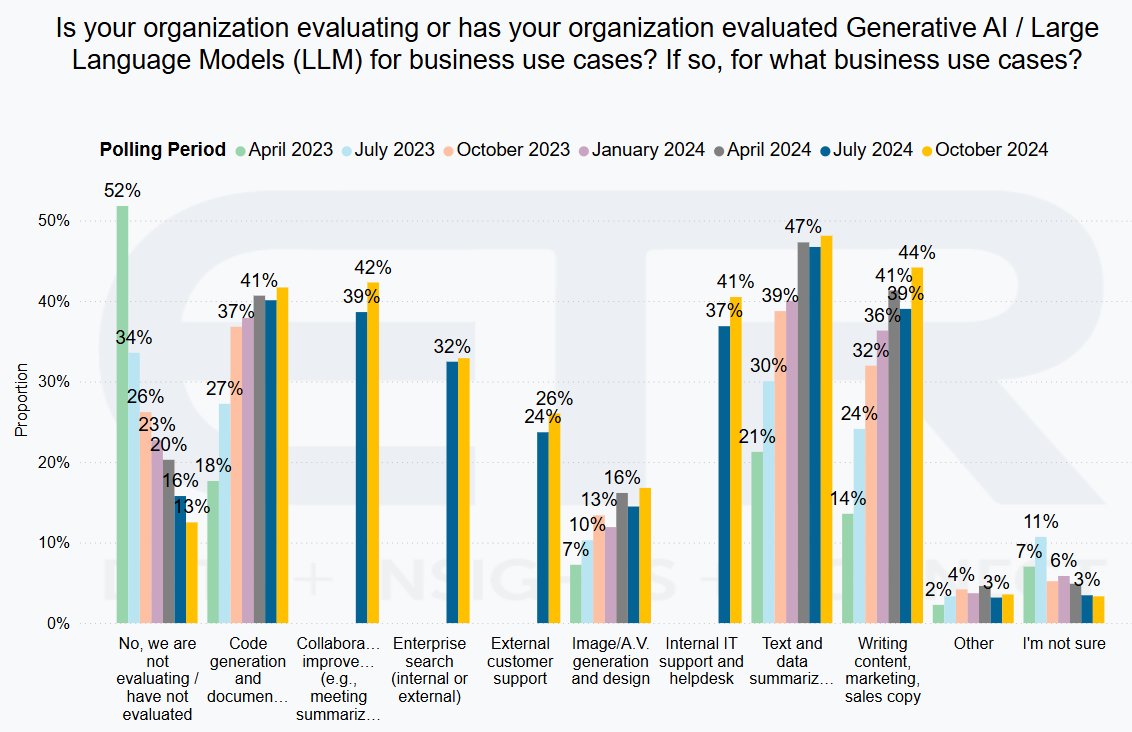
ETR Data: In ETR’s July 2024 State of Gen AI survey (above), less than 20% of respondents say that their organization is NOT evaluating generative AI / LLMs. This number has consistently fallen each survey period. Text and data summarization, marketing and sales content writing, along with code generation and documentation, are the most evaluated business use cases.
Part 2: Interview Highlights
Increased productivity with AI. Yahav realized early on that software’s repetitive nature made it prime for automation. “When we started, the technology was not completely there, but we knew that AI and machines in general are going to take a significant part in the creation and maintenance of software moving forward.” Tabnine’s ambition was to create a system where developers could describe a service or application, and AI would generate high-quality code, with tests to ensure accuracy. AI code generation is now mainstream, and companies are adopting rapidly. “I'm happy to say that this vision is really getting realized now with it at a massive scale. Our customers report between 20% to 50% improvement in productivity.” AI tools have hit a “sweet spot,” boosting developer productivity with minimal effort and only slight adjustments to existing workflows. “You don't need special training. You just work, and it helps make you more productive.” Automatically generated code is now found throughout the software development lifecycle, from planning, to code generation, testing, code review, and deployment, though human engineers typically still oversee all.
The importance of trust. However, Yahav sees AI coding assistants soon evolving into more autonomous AI agents capable of completing discrete tasks, and ultimately into full-fledged “AI engineers,” which will drive development all the way from ideation to production deployment. “The job description of an AI engineer is very similar to the job description that you would write for a [human] engineer.” AI engineers must understand a company’s particular needs, and be inquisitive, communicative, and self-aware enough to alert when code they generate may need human review. “There’s a validation phase, which is critically important and separate from generation. During the validation phase, AI is used to check the security and performance of whatever got generated—because we need to trust that—and then there is a final review phase that is done by the AI together with the human.”
The Tabnine architecture. At the core of Tabnine's architecture are proprietary coding models, third-party LLMs, and customer database integrations. “You can connect online to any LLM; we always give our customers the best models out there. We also come with our own set of LLMs that are specifically trained only on permissibly licensed open-source code, so we can guarantee that you don't get IP pollution or any IP risks when you consume code that has been generated by Tabnine.” Internal integrations ensure that AI has the same level of contextual awareness as a human engineer; Tabnine uses retrieval augmented generation (RAG) to aggregate and correlate data across systems like Datadog, Snyk, Docker, and Atlassian products, creating a holistic view that no single system could otherwise offer. “[It] will see previous support tickets, these crash logs, Jira tickets, and Confluence documentation on best practices. It will become aware of everything that exists in the organization, and this will provide context or will inform Tabnine as it's trying to accomplish these tasks.”
More powerful than any one LLM is the comprehensive context Tabnine builds into its prompts, which incorporates the above data and an additional control layer. “Control is critically important, because it allows you—the architect or the developer—to communicate standards and best practices, policies, permissions, and all sorts of information that says, ‘[AI], I don't care what you’ve learned. Let me give you some additional information. Here's how you should do a certain thing.’” On top of this are validation agents, which leverage different models. “Validation agents have a completely separate set of capabilities designed just to make sure that what goes into the code base at the end kind of follows the right practices, as the architect—or whoever is in charge of the code or the best practices—wants to set them.”
Yahav emphasizes the complexity and depth of Tabnine’s retrieval process, compared to a more simplistic industry understanding of RAG. “People always say ‘RAG’ as if it’s one thing, but relative retrieval is an entire research area. [Our] component does retrieval, looks at the local project, and retrieves the relevant documents. It can be a piece of code, it can be an actual document, or it can be a paragraph. It can be whatever you decide the granularity of documents to be.” While the concept of “retrieval” remains consistent, the algorithms and mechanics used can vary significantly depending on the sources of information. “You also have [model] fine-tuning available, which means taking customer code and creating a custom model [distinct from] the universal model. You keep doing the same thing that you did with integration, but rather than hitting the universal model, you are now hitting a special custom model created based on the customer.”
The full summary report and replay for both parts 1 and 2 can be accessed on the ETR Platform:
Summary Part 1 | Summary Part 2 | Webinar Replay Part 1 | Webinar Replay Part 2
If you don't have access, you can get started on the ETR research platform today or reach out to us and request a copy
Enterprise Technology Research (ETR) is a technology market research firm that leverages proprietary data from our targeted IT decision maker (ITDM) community to provide actionable insights about spending intentions and industry trends. Since 2010, we have worked diligently at achieving one goal: eliminating the need for opinions in enterprise research, which are often formed from incomplete, biased, and statistically insignificant data. Our community of ITDMs represents $1+ trillion in annual IT spend and is positioned to provide best-in-class customer/evaluator perspectives. ETR’s proprietary data and insights from this community empower institutional investors, technology companies, and ITDMs to navigate the complex enterprise technology landscape amid an expanding marketplace. Discover what ETR can do for you at www.etr.ai